1) DP와 MC 기법의 장단점

DP기법의 경우 각 상태와 행동의 관계를 최대한 활용해 계산량을 줄인다는 장점을 가진 반면에
환경에 대한 모델이 없으면 계산이 불가능하다는 단점을 가지고 있다.
MC기법의 경우 환경에 대한 선험적 지식이 필요없으며 불편추정량을 가진다는 장점이 있지만
각 상태와 행동의 관계에 대해서 전혀 활용하지 않으며 분산이 크고 문제구조를 반영하지 않는 추정이라 다소 비효율적일 수 있다는 단점이 존재한다.
Temporal-difference 기법은 DP와 MC의 장점을 합친 장점을 가지고 있다.
각 상태와 행동의 관계를 최대한 활용하고, 환경에 대한 선험적 지식이 필요없다는 장점을 가진다.
하지만 불편추정량이 아니어서 MC기법과 다르게 어느정도의 추산오차가 발생할 수 있다는 단점이 있다.
지난 포스트에서 봤던 Incremental MC기법을 돌아보면 다음과 같다.

Temporal - difference(TD)기법의 개념은 다음과 같다.

TD target이라는 개념이 등장한다. $V(s)$를 조정할 때 목표치가 되는 개념이다.
TD error ($\delta_t$)는 TD target 에서 현재 $V(s)$를 뺀 것으로 TD target과의 오차를 의미한다.
2) MC vs. TD

이 표를 보면 MC와 TD의 차이점이 확실하게 보인다.
MC기법은 편향이 없는 대신 높은 분산을 가진다.
때문에 좋은 추정치를 얻기 위해서는 많은 시행이 필요하다.
TD기법은 편향이 존재하는 대신 낮은 분산을 가진다.
때문에 시행햇수와 무관하게 상태,행동 가치함수의 추정에 오류가 존재한다.
하지만 추정치의 분산이 낮기 때문에 빠른속도로 충분히 좋은 추정치를 얻을 수 있다.
또한, MC기법은 문제가 정확하게 Markovian이 아니어도 정확한 추산치를 계산할 수 있으나 효율성이 떨어진다.
TD기법의 경우 문제가 정확하게 Markovian이 아니면 정확학 추산치를 계산할 수 없다. 하지만 빠르게 추산할 수 있다.

그리고, MC기법의 경우 에피소드가 Terminal state(종결상태)에 도달해야만 학습 진행이 가능한 반면, TD기법의 경우 Terminal state(종결상태)까지 가지 않아도 학습을 진행 할 수 있다.
3) n - step TD

n-step TD란 n스텝까지의 보상(새로운정보) + 가치함수(알고 있는 정보)를 $G^{(n)}_t$로 사용하는 것이다.
※ $\infty$-step TD의 경우 몬테카를로 기법과 동일하다.
여기서 step의 수 n이 증가하면 더해야 하는 보상의 수가 많아지므로 자연스럽게 분산이 증가하게 된다.
반대로, step의 수 n이 감소하면 더하는 보상의 수가 적어지므로 편향이 증가 할 수 있다.
n - step TD기법을 Python코드로 구현하면 다음과 같다.
total_eps = 10000
log_every = 1000
def run_episodes(env, agent, total_eps, log_every):
values = []
log_iters = []
for i in range(total_eps+1):
run_episode(env, agent)
if i % log_every == 0:
values.append(agent.v.copy())
log_iters.append(i)
info = dict()
info['values'] = values
info['iters'] = log_iters
return info지난 포스트에서 봤던 MC기법의 run_episodes와 차이가 없어보인다.
MC기법과 TD기법의 차이는 run_episode함수 내 update함수에서 보여진다.
< n - step TD 알고리즘 변수 및 함수 설명 >
TD기법의 agent는 초기화 시 사용하는 인수가 추가되었다.
TDAgent :
class TDAgent:
def __init__(self,
gamma: float,
num_states: int,
num_actions: int,
epsilon: float,
lr: float,
n_step: int):스텝수에 해당하는 n_step이 추가되었고, 이 TDAgent의 객체가 agent에 들어가게 될 것이다.
run_episode(env, agent) :
def run_episode(env, agent):
env.reset()
states = []
actions = []
rewards = []
while True:
state = env.observe()
action = agent.get_action(state)
next_state, reward, done, info = env.step(action)
states.append(state)
actions.append(action)
rewards.append(reward)
if done:
break
episode = (states, actions, rewards)
agent.update(episode)- run_episode 함수 역시 MC기법과 동일한 것으로 보인다.
※ MC기법 알고리즘의 설명이 기억나지 않는다면 여기를 참고하자.
Part2 - 5. 몬테 카를로 정책추정 (Monte-carlo prediction: MC prediction)
지난 포스트까지는 환경에 대한 정보가 주어질 때를 가정하였을 때의 강화학습 풀이기법인 동적계획법 (Dynamic Processing : DP)를 살펴보았다. 정책 반복에서 가치반복으로, 가치반복에서 비동기 DP
hh-bigdata-career.tistory.com
agent.update(episode) :
def update(self, episode):
states, actions, rewards = episode
ep_len = len(states)
states += [0] * (self.n_step + 1) # append dummy states
rewards += [0] * (self.n_step + 1) # append dummy rewards
dones = [0] * ep_len + [1] * (self.n_step + 1)
kernel = np.array([self.gamma ** i for i in range(self.n_step)])
for i in range(ep_len):
s = states[i]
ns = states[i + self.n_step]
done = dones[i]
# compute n-step TD target
g = np.sum(rewards[i:i + self.n_step] * kernel)
g += (self.gamma ** self.n_step) * self.v[ns] * (1 - done)
self.v[s] += self.lr * (g - self.v[s])뭔가 바뀐게 엄청나게 많아보인다.
TD기법의 업데이트 수식을 다시한번 상기시켜 보자
$$ V(s) \leftarrow V(s) + \alpha (G_t - V(s)) $$
$$ G_t^{n} = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + \cdots + \gamma^{n-1} R_{t+n} + \gamma^n V(S_{t+n}) $$
states와 rewards와 dones를 업데이트 해주는 부분을 보자.

간단하게 도식화를 해보았는데, 첫줄의 states, actions, rewards = episode에서 states와 rewards를 받아온 것이 있을 것이다.
여기서 n_step + 1만큼 길이를 추가해 주는 이유는 에피소드의 마지막 부분(종결시간 T)에서 $G_t$를 구할 때,
$R_{T+1}, R_{T+2}, R_{T+3}, R_{T+4}$에 해당하는 부분이 존재하지 않으므로 인덱싱오류가 발생하는 것을 방지하기 위함과 동시에 종결상태 이후의 보상은 모두 0이므로 위와같이 지정해준 것이다.
또한 dones는 처음부터 episode의 길이만큼은 0을 삽입, (n_step + 1)만큼은 1을 삽입해주는데 이는
done의 역할을 알아야 이해하기 쉽다.
다음 코드를 살펴보자
td_target = reward + self.gamma * self.v[next_state] * (1 - done)done이 1일 경우 self.v[next_state]에 0이 곱해져 종결 이후의 가치값은 더이상 업데이트에 반영되지 않도록 하는 역할을 한다.
kernel의 경우 $1, \gamma, \gamma^2, \cdots, \gamma^{n-1}$로 이루어 져있다.
np.sum(rewards[i : i + self.n_step]) * kernel은 numpy의 특성에 따라
$R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3}$가 될 것이고,
마지막 부분 $\gamma^3 V(S_{t+3})$이 빠져있는 것을 볼 수 있다. (3 - step TD를 가정)
따라서 g += (self.gamma ** self.n_step) * self.v[ns] * (1 - done) 를 통해
$\gamma^3 V(S_{t+3})$에 해당하는 부문을 추가해주는 것이고
그 결과 g는 $R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3}$+ $ \gamma^3 V(S_{t+3})$ 이 되는 것이다.
(TD target)
그다음 V(s)를 업데이트 해주는 줄이 나오고 해당 함수는 끝이난다.
4) 1-step TD vs. 5-step TD vs. MC
앞에서 n이 $\infty$인 경우 MC와 동일한 수준이라고 했다.
그렇다면 n과 error의 관계를 살펴볼 수 있을 것이다.
1-step, 5-step, MC 기법 별 오차를 살펴보자.
오차는 DP를 이용해 구한 $V^{\pi}$와 각 기법의 $V^{\pi}$간 차이로 지정했다.

임의의 Gridword 환경을 부여하고 총 10회의 반복 내 3000회의 episode들을 주어 학습시켰다.
진한 선은 10회의 반복동안의 오차평균이고, 연한 지역은 $\pm \sigma$에 속하는 부분을 표현했다.
n이 가장 크다고 볼 수 있는 MC의 경우 참값에 빠르게 수렴한다고 볼수 있다.
그러나 분산이 크다는 단점이 존재했다.
n이 가장 작은 1-step TD의 경우 참값에 가장 느리게 수렴하며 총 시행 후에도 편향이 존재함을 볼수있다.
하지만 분산은 매우 작은 것을 눈으로 확인 할 수 있다.
따라서 n과 분산은 비례관계, n과 편향은 반비례관계라고 볼 수 있다.
그렇다면 적절한 n을 어떻게 설정해야 하는가??
n을 설정해주지 않고 여러개의 추정치를 하나의 추정치로 표현할 수는 없을까?
그림7.과 같이 단순히 산술평균을 낸다면

현재 정보만을 가지는 $G_t^{(1)}$는 상대적으로 적은 분산을 가지나, 편향이 있을 것이고
미래의 정보를 모두 사용하는 $G_T^{(T)}$는 큰 분산을 가지나, 편향이 없을 것이다.
이 때, 추가적으로 필요한 장치에는 2가지가 있다 :
1. 편향 - 분산 트레이드 오프를 조정할 수 있는 방법
2. 각 추정치를 "적합하게" scaling 하는 요소
이를 적용하여 만든 것이 TD($\lambda$)이다.
5) TD($\lambda$)
TD($\lambda$)의 경우 기하적으로 감소하는 $\lambda$가 존재하며 가중치의 역할을 수행한다.
(n이 커질수록 -> 가중치 감소, n이 작을수록 -> 가중치 증가)

그렇다면 $\sum$앞에 (1 - $\lambda$)는 왜 붙어있을까?
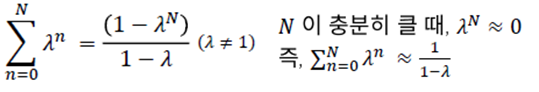
그림9.에서, N이 충분히 크면 $\sum_{n=0}^{N} \lambda^{n}$이 $\frac{1}{1-\lambda}$가 된다.
이 때 scale 보정장치를 해주는 역할을 하는 것이 (1 - $\lambda$)인 것이다.
결론적으로, TD($\lambda$)에서는 $\lambda$를 조정함으로써, 분산 - 편향 관계를 조정할 수 있다.
- TD(0) ($\lambda$ = 0 일 때), $G_t^0$ = $G_t^{(1)}$ (1-step TD와 동일)
분산 ↓, 편향 ↑
- TD(1) ($\lambda$ = 1 일 때), 매 방문 MC와 유사
분산 ↑, 편향 ↓
여기서 이제, $\lambda$를 결정하는 것이 분석가의 몫인 것이다.
내 생각 :
에피소드를 종결상태까지 끝내야만 업데이트 되는 MC에 비해 TD는 시간적인 면에서 상당히 큰 이점을 가진 것 같다.
하지만 TD기법에도 단점이 존재했다.
편향이 존재한다는 것이다.
MC기법은 분산이 크고, TD기법은 편향이 크고. 대략난감이었다.
이를 해결하기 위한 기법이 TD($\lambda$)기법인데 여기서 $\lambda$를 조정하는 일에도 상당히 큰 시간을 쏟아부어야 할 것 같다는 생각이 든다.
더 좋은 방법을 찾을 때 까지 계속 공부해보자!
참고자료 :
강화학습 A-Z 강의자료
'강화학습 강의 복습노트' 카테고리의 다른 글
| Part2 - 8. SARSA : TD기법을 활용한 최적 정책 찾기 (0) | 2020.12.26 |
|---|---|
| Part2 - 7. MC Control : MC기법을 활용한 최적 정책 찾기 (0) | 2020.12.26 |
| Part2 - 5. 몬테 카를로 정책추정 (Monte-carlo prediction: MC prediction) (0) | 2020.12.25 |
| Part2 - 4. 비동기적 동적계획법 (0) | 2020.12.23 |
| Part2 - 3. 동적계획법 (Dynamic Programming) (0) | 2020.12.23 |



